Trunk-Based Development for Beginners: Rules, Styles, and Release Strategies
Introduction
Trunk-Based Development is a branching model used within source control tools, such as git. When using Trunk-Based Development, developers collaborate on the trunk, often called main. They either commit directly to the trunk or use short-lived feature branches.
When I say short-lived feature branches, I mean really short-lived. This is all to avoid long-lived development branches and the conflicts that can happen when merging them.
The goal of Trunk-Based Development is to provide high throughput using continuous integration (CI) and continuous delivery (CD). It benefits from short iterations, and especially the use of stories that take hours - not days - to complete. Because of this, it is not particularly compatible with waterfall but is very compatible with small broken down stories.
It would perhaps be useful to briefly discuss Git Flow, as an alternative to Trunk-Based Development, before diving deeper. This is to give you something concrete to compare Trunk-Based Development against.
An alternative: Git Flow
Git Flow is an alternative branching model, which uses the following branches: main, develop, feature, release and hotfix.
The main branch is used to contain production-ready code that can be released, whereas the develop branch is used to contain newly developed features that are in the process of being tested. Development work actually happens on feature branches, which branch off of develop and are merged back into develop when a feature is complete.
Release branches also branch off of develop, once the develop branch has reached the desired state of the release. Once a release branch is created, only bug fixes should be added to it. Bug fixes should be merged back into the develop branch. Once a release branch is ready for deployment after some QA, it is merged into main and released.
Of course, things can go wrong and might require a hotfix. Here, a hotfix branch is created that branches off of main. Developers perform the bug fix and merge it into both develop and main. Once merged into main, another deployment is performed.
This is quite process heavy and there are a lot of branches. While this steady approach can be useful, in that it allows us to be confident before a release, it can be quite slow. There is also the risk that regressions could easily happen; if a release or hotfix branch with bug fixes on is never merged back into develop then regressions will happen.
Key rules
Trunk-Based Development does away with the branch heavy approach of workflows such as Git Flow. It does still require some key rules.
- Anything that is merged into the trunk - the main branch - should always be ready for release.
- Developers should either commit straight to the trunk or use short-lived feature branches that last no longer than a few days.
- Releases either happen directly from the trunk or using release branches.
- Branches must be deleted upon merging into the trunk.
- CI checks must be ran prior to commits to main to limit the risk of the trunk breaking.
What is CI / CD
Throughout this post I reference continuous integration (CI) and continuous delivery (CD). You may be wondering what these are. They are quite large topics related to the DevOps world, but I can summarise them here.
CI is, simply put, the frequent merging of code from different developers to a single branch. Developers will frequently, or continuously, integrate their code together to ensure it works with other changes. CI relies on pipelines that run automatic tests and builds to validate that the code changes work together.
Trunk-Based Development heavily utilises CI pipelines as they validate that code recently merged into the trunk does not break the trunk build. Some workflows use CI pipelines to revert commits that break the trunk build.
CD expands upon CI by adding release steps upon the success of a CI pipeline. The CD pipeline may release versions to environments such as QA, UAT or production. Release steps may also build new infrastructure.
Styles of Trunk-Based Development
There is not one-size fits all with Trunk-Based Development and indeed there are different "styles" of Trunk-Based Development. These are committing directly to the trunk or using short-lived feature branches.
Committing Straight to the Trunk
This approach really does what it says on the tin. Developers commit their changes directly to the trunk. They should only commit changes that work and are releasable.
This approach has incredibly high-throughput and really does work best with pair programming if the organisation views pair programming as not needing a strict code-review.
The throughput comes at a cost. The build is incredibly easy to break. Teams validate that the build isn't broken by using CI pipelines, which need to run incredibly fast. Why the need for speed? Let's say a team has multiple pairs of developers, at any point any number of these pairs could commit their changes to the trunk. The developers need a CI pipeline to inform the pairs that their changes have passed before a commit from another pair hits the trunk, so that they know that the build either hasn't been broken or, if it has, which commit broke it.
Often the pipeline is kept quick by neglecting further tests, which makes it more likely that the CI pipeline would not catch changes that would cause the build to break.
A solution would be to have developers run a full build, as the CI pipeline would, before committing to the trunk. Teams could also have a bot that reverts commits that break the trunk.
All in all, the high throughput comes at the cost of the trunk being more likely to break. Safeguards must be in place for this approach.
Short-Lived Feature Branches
An alternative to committing straight to the trunk is using short-lived feature branches.
How short-lived? No longer than a few days.
Each feature branch should be maintained by either one developer or two, if pair programming is being used. No other developers should use the branch unless they are reviewing the changes. No branching off of a feature branch!
A feature branch should only be merged into the trunk when that feature branch is being closed and when the work is releasable. Merging the trunk into a feature branch or rebasing the feature branch off of the trunk is allowed so as to keep the feature branch up to date with the latest changes and to stop any merge conflicts when it comes to merging the release branch.
With short-lived feature branches it does not need to be the case that each user story or ticket maps to one branch being merged. A piece of work could have multiple branches being merged to the. The could be a branch merging for the initial work, followed by another branch for refactoring. The most important thing is that each merge is able to go live.
Compared to committing straight to the trunk, the throughput is obviously slower. A fast CI pipeline is, however, less necessary. It also means that there can be explicit code reviews each time a PR is merged. Throughput is being sacrificed for the benefit of safety.
Managing Change
When merging into the trunk, all changes should be releasable. Not all code that goes into the trunk needs to be used. That is, the code may exist but not actually be used by the users, as the code is not "active". This allows developers to make incremental changes, with the code being deployed, but only activate the parts of the codebase that are complete and useable.
Branch by Abstraction
Branching by Abstraction is a method for slowly replacing a service that is undergoing change.
Let's say there is a service, S, that we wish to replace. S, is used by clients A, B and C.
To perform branching by abstraction, we would use the following steps:
-
Create an abstraction layer in front of S and point the clients at that abstraction layer rather than directly at the service.
-
Build a new version of S, called T. T is what we want to replace S with. T would sit behind an abstraction layer that to the clients looks the same as the one that S sits behind.
-
Build the logic within T that only client A uses.
-
Once completed we would point A to use the abstraction layer for T. At that point, A is using T rather than S, but the client - and user - is not aware that a new service is being used. B and C remain using S.
-
Repeat steps 3 and 4 for the other clients, B and C. Slowly, we would be using S less and T more.
-
Once no client is using S, remove S. Service S has now been fully replaced by service T.
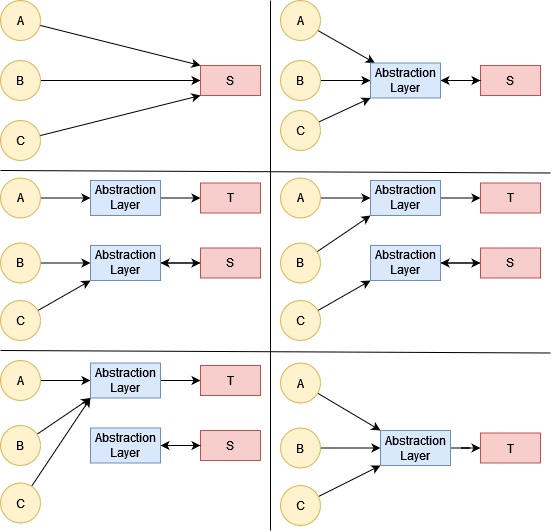
Each of these steps are small releasable steps, which keeps us following the rules of Trunk-Based Development. Branching by Abstraction is all about making small managable changes to replace a service.
Of course a downside to this is that for a period two services need to be maintained; the alternative would be doing one large switch-over. One large switch-over may still follow Trunk-Based Development, as we would not activate the new service until we are ready to switch over, but it comes with the risk of introducing many bugs at once.
Feature Flags
Feature flags, simply put, are toggles for different features within our applications. They can be used to enable and disable different features within an application.
A common approach is wrapping part of the application code in if statements, and only trigger the code if the feature flag is active. Feature flags can be enabled or disabled via config at build time. A remote service may also be used to call the feature flags and then check which flags are active; this allows feature flags to change during runtime.
In the context of Trunk-Based Development, feature flags allow changes going into the trunk to be disabled. Therefore, if a feature has some code in the trunk but is not ready to be used it is still releasable. This is because if the feature flag is disabled, a user would never see the unready code.
Though simple, there are a few downsides to feature flags. Developers need to continuously review feature flags. It is easy for old feature flags to remain in the codebase but with their values never changing. This makes them redundant code that should be removed. Both paths of the feature flags also need to be tested and maintained. It can be quite easy for feature flags to clutter the codebase if they are not removed when they are no longer necessary.
Release Strategies
There are different release strategies within Trunk-Based Development. We can release directly from the trunk or using release branches.
Directly From the Trunk
In Trunk-Based Development, every commit to the trunk is releasable. Therefore, it goes without saying, that we can release from any commit. This allows for a high release cadence, however it does leave a codebase prone to bugs.
A CI pipeline passing when changes have been merged into the trunk does not guarantee that the changes are bug free. Some other forms of QA should take place. Therefore, when releasing directly from the trunk an organisation should take a "fix-forward" attitude.
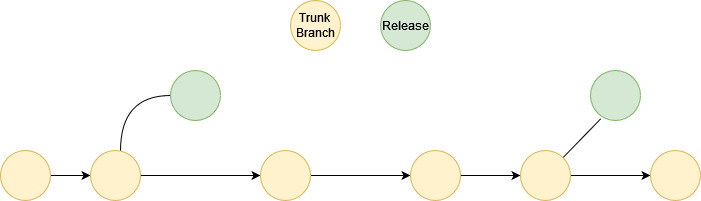
Release Branches
When using branches for release, an organisation will make a release branch shortly before a release is scheduled. This keeps the release branch independent from the work going into the trunk; after all, the work going into the trunk may not break the build, but it may introduce new bugs.
Release branches should not directly receive any continued development work. You may be wondering what should happen if there are bugs in the release branch? In that instance, bugs would be fixed on the trunk and then cherrypicked into the release branch. This solves the issue of regressions discussed in the GitFlow section.
It is key that we cherrypick bug fixes from the trunk rather than merge them. We want our release branches to be snapshots of the trunk, with an optional number of bug fixes cherrypicked in. Release branches should also not be merged back into the trunk; there would be no point in this as they only contain changes that are already on the trunk.
Once we are happy with the state of the release branch, we release it. The release branch should not deleted until a subsequent release is performed. At that point, the release branch should be deleted.
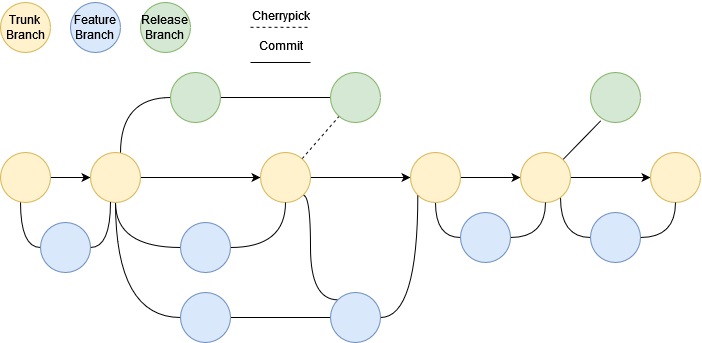
Summary
Trunk-Based Development is a branching model that has developers committing frequently to a trunk branch, which is always releasable. There are various styles of Trunk-Based Development, whether that's committing straight to the trunk or using short-lived feature branches. It relies on CI / CD to validate that builds pass and that developers are not breaking the build.
There are different ways of managing changes - via feature flags and branching by abstraction, to name only a couple. Different methods for managing releases also exist, in the form of releasing straight from the trunk vs. utilising release branches.
Trunk-Based Development enables high-throughput, but does require safeguards and rules to be place. It may not work for every organisation but - in an agile environment - it is worth exploring.